
Last updated on March 30th, 2026
Businesses a long time back had already recognized the importance of data when it comes to an understanding of their customers and making strategic decisions for increased ROIs.
However, in the scramble to be bring customized product and solutions, crucial facts about data quality gets sidelined, which leads to incorrect analytical inferences and costly business decisions.
Gartner says, “The average financial impact of poor data quality on organizations is $9.7 million per year.” You can improve the quality of data by ensuring accurate data entry points, effective data amalgamation, data standardization, and data cleansing methods.
Practical application of data cleansing and enrichment techniques can aid in creating, validate, update, enhance, and enhance business-critical data by developing custom tools (spiders, bots, and scripts) and manual processes.
Here are some implications of bad data:
- Ovum Research reports poor data quality costs businesses at least 30% of their revenue.
- Incorrect sales data pushes salespersons to waste time on dead leads. Inaccurate data can steer the business towards skewed strategies.
- MarketingSherpa states that every year 25-30% of data goes corrupt. Bad data can give distorted info about customer demographics and purchasing behaviors, which would lead to missed opportunities for marketers.
- Miss-communication is a massive turn-off for customers. Bad data can contribute to miscommunication to customers, a sense of dissatisfaction among them, and even negative branding on social media.
What is data cleansing?
Data cleansing or data cleaning is a method of spotting and rectifying debase or inaccurate records from a recordset, table, or database. It refers to detecting piecemeal, incorrect, imprecise, or unrelated parts of the data and then substituting, modifying, or removing the dirty or rough data.
Data cleansing may be executed interactively with data wrangling solutions, or as batch processing by scripting. After sanitizing, a data set should be coherent with other similar data sets in the system.
The discrepancies detected or removed may have been initially caused by user entry inaccuracies, by distortion in transmission or storing, or by dissimilar data dictionary definitions of the same entities in different stores.
Data cleansing differs from data authentication in that validation almost unvaryingly means data is excluded from the system at admission and is achieved at the time of entry, rather than on sets of data.
The actual procedure of data cleansing may comprise removing typographical errors or authenticating and correcting values compared to a known list of objects. The validation may be stringent (such as declining any address that does not have a valid zip code) or fuzzy (such as rectifying records that in some measure match existing, known accounts).
Some data cleansing tools will clean data by cross-checking with an authenticated data set. A typical data cleansing practice is data enhancement, where data is made complete by adding related information—for example, appending locations with any phone numbers associated with that address.
Data cleansing may also encompass synchronization (or normalization) of data, which is the process of getting together data of “variable file formats, nomenclature, and columns,” and changing it into one cohesive data set; a simple example is an expansion of acronyms.
How to clean data?
Clean data is the foundation of significant research and insights. Therefore, data science execs spend 80% of their time in data cleansing and normalizing. Data Cleansing follows various approaches.
Data auditing
Audit the data using statistical and database methods to detect anomalies and contradictions: this eventually indicates the characteristics of the peculiarities and their localities.
Several tools will let you postulate checks of various kinds (using a grammar that imitates a standard encoding like JavaScript or Visual Basic) and then generate code that examines the data for breach of these constraints.
I have explained the process below in “workflow specification,” as well as “workflow execution.” For users that lack access to high-end cleansing tools, Microcomputer database management systems such as MS Access or else File Maker Pro will also let you achieve such authorizations on a limit-by-limit basis, interactively with light or no programming necessary in many cases.
Workflow specification
Have a workflow for the detection and removal of anomalies. It starts after the procedure of auditing the data and is crucial in accomplishing the end product of high-quality data. Creating a proper workflow needs close monitoring of the causes of the anomalies and errors in the data.
Workflow execution
In this stage, execute the workflow after its requirement is complete, and its accuracy is confirmed.
The application of the workflow should be well-organized, even on vast sets of data, which unavoidably poses a trade-off since the carrying out of a data-cleansing process can be computationally costly.
Post-processing and controlling
After completing the cleansing workflow, inspect the results to verify correctness. Adjust the incorrect data left post-execution of the workflow manually, if conceivable.
The result is a new sequence in the data-cleansing procedure where you audit the data again to permit the requirement of an additional workflow to cleanse the data by automatic processing further.
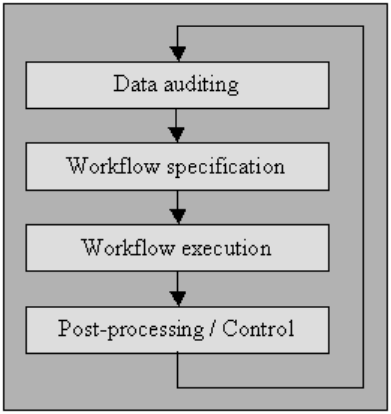
A better quality source data has to do with “Data Quality Culture,” and every organization must initiate it at the top of the business establishment.
It is not just a matter of executing secure validation checks on input screens, because almost no matter how careful these checks are, they can often still be bypassed by the users.
There is a nine-step guide for establishments that wish to improve data quality:
- Declare a high-level assurance to a data quality culture
- Drive procedure reengineering at the policymaking level
- Spend dough to advance the data entry setting
- Spend money to develop application integration
- Devote money to alter how processes function
- Endorse end-to-end team responsiveness
- Encourage interdepartmental collaboration
- Publicly reveal data quality superiority
- Unceasingly measure and advance data quality
Others consist of:
Parsing
for the recognition of syntax errors. A parser chooses whether a string of data is acceptable within the allowed data specification. It is akin to the way a parser toils with syntaxes and languages.
Data transformation
Data transformation lets the plotting of the data from its given format into the arrangement expected by the appropriate application. It incorporates value conversions or translation procedures, as well as standardizing numeric values to follow the minimum and maximum values.
Duplicate elimination
Duplicate detection needs an algorithm for defining if the data has duplicates of the same entity. Usually, data is arranged by a key that would bring identical entries closer for faster identification.
Statistical methods
By examining the data using the values of mean, standard deviation, range, or clustering procedures, an expert can find values that are unanticipated and thus incorrect.
Even though the correction of such data is steep since the actual denomination is not known, however, you can resolve it by setting the values to an average or other statistical value.
One other use of statistical methods has to handle lost denominations, which can be substituted by one or more possible values, which are usually acquired by extensive data augmentation algorithms.
Data hygiene or Data quality
Data to be processable and interpretable effectively and efficiently, it has to satisfy a set of quality criteria. Data meeting those quality criteria is said to be of high quality. In general, an aggregated value over a set of quality criteria is data quality.
Starting with the quality criteria specified in, we describe the set of standards that are affected by comprehensive data cleansing and define how to assess scores for each one of them for an existing data collection.
For measuring the quality of a data collection, evaluate the ratings for each of the quality criteria.
Using the assessment of scores for quality criteria can be a way to quantify the necessity of data cleansing for data collection as well as the success of a performed data cleansing process on a data collection.
You can use quality criteria within the optimization of data cleansing by specifying priorities for each of the requirements, which in turn influences the execution of data cleansing methods affecting the specific rules.
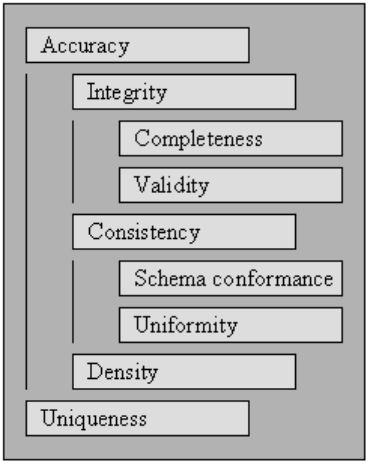
Validity
The point to which the data fit into defined business rules or constraints.
- Datatype Constraints: values in a particular column must be of a specific data type, e.g., boolean, numeric, date, etcetera.
- Range Constraints: typically, numbers or dates should be within a specific range.
- Mandatory Constraints: specific columns cannot be blank.
- Unique Constraints: a field, or a blend of areas, must be distinctive across a dataset.
- Set-Membership constraints: denominations of a column emanate from a set of discrete values, e.g., enum values. For example, gender may be male, female, or others.
- Foreign-key constraints: as in relational database systems, a foreign key column should exist in the referenced primary key.
- Regular expression patterns: Text fields should follow a specific design. For example, phone numbers need to obey a particular profile (xxx) xxx-xxx.
- Cross-field validation: specific settings that span across numerous fields must hold, e.g., a patient’s date of release from the hospital cannot be before the time of admittance.
Accuracy
The degree to which the data is near to the actual values. While outlining all possible valid field values permits invalid values to be easily spotted, it does not mean that they are accurate.
A valid street address mightn’t exist. A person’s eye color, say blue, might be correct, but not right. One other thing not to forget is the difference between correctness and precision.
Saying that you live on the planet earth is proper. But, not precise. Where on the planet? Assuming that you live at a particular street address is more accurate.
Completeness
The point to which all required data is known and assimilated.
Data will be missing for various causes. One can mitigate this issue by questioning the source.
Possibilities are, you are either going to get a different answer or will be challenging to ascertain again.
Consistency
The degree to which the data is unfailing, within the matching data set or across several similar data sets.
Inconsistency happens when two values in the data set controvert each other.
A valid age, say 10, mightn’t match with the marital status, say divorced. Recording a customer in two different tables with two separate addresses is an inconsistency.
Which one is true?
Uniformity
The degree to which the data specified is utilizing the same unit of the gauge.
The weight in pounds or kilos, a date in the USA format or European format, and the currency sometimes in USD or YEN.

V. Subramanyam
Head of Product at Ampliz | Healthcare Data & GTM Intelligence Expert
V. Subramanyam is the Head of Product at Ampliz, where he leads the strategy and development of healthcare data intelligence solutions that help sales, marketing, recruiting, and commercial teams identify and engage healthcare decision-makers across the United States.
With extensive experience in product management, healthcare data, B2B SaaS, GTM strategy, and sales intelligence, he focuses on building products that simplify healthcare prospecting through accurate physician, hospital, executive, and healthcare organization data. His work emphasizes data quality, enrichment, and AI-powered workflows that enable organizations to make faster, data-driven decisions.
Connect with Him:
- LinkedIn: https://www.linkedin.com/in/vsubramanyam
- Company: https://www.ampliz.com

ZoomInfo Pricing Plans? How Much Does ZoomInfo Cost?

Why Your Traffic Stopped Growing and How an SEO Expert Diagnoses It

Why Your Outreach Fails Without Accurate Hospital & Physician Data

Why You Can’t Market to a Cardiologist the Same Way You Market to a Pediatrician

Why Specialty-Level Physician Data Drives Better Campaign ROI in Healthcare Marketing

Why Data Accuracy Matters in Legal Cases Against Negligent Nursing Homes
